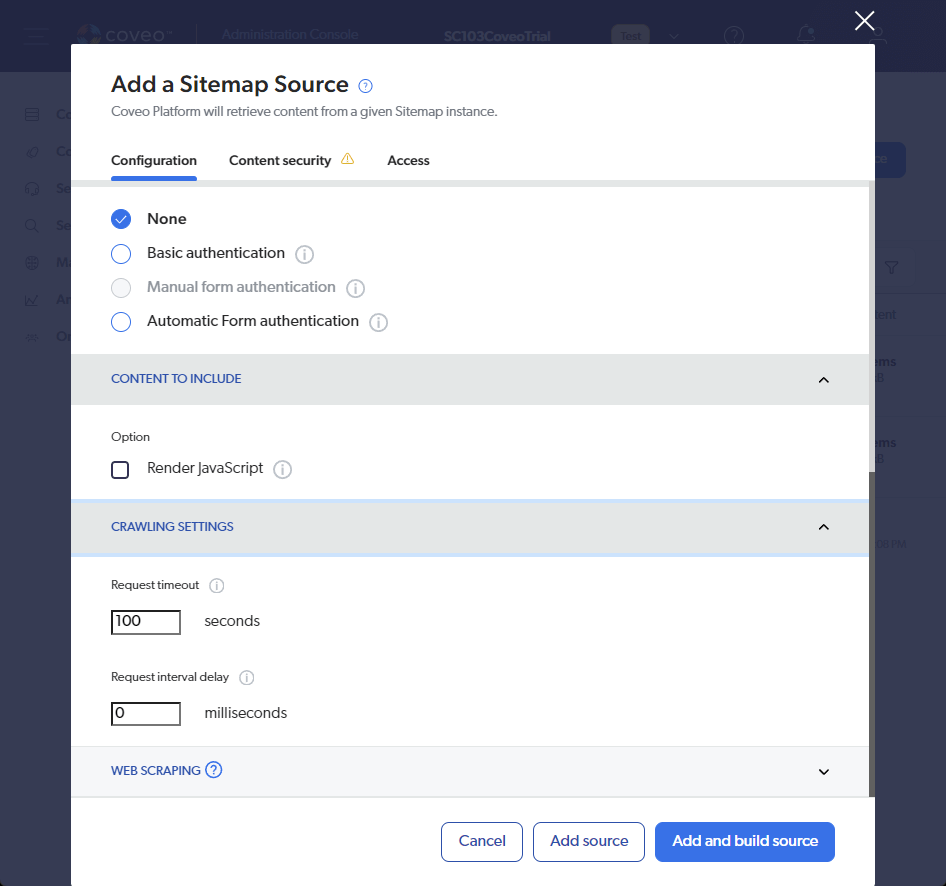
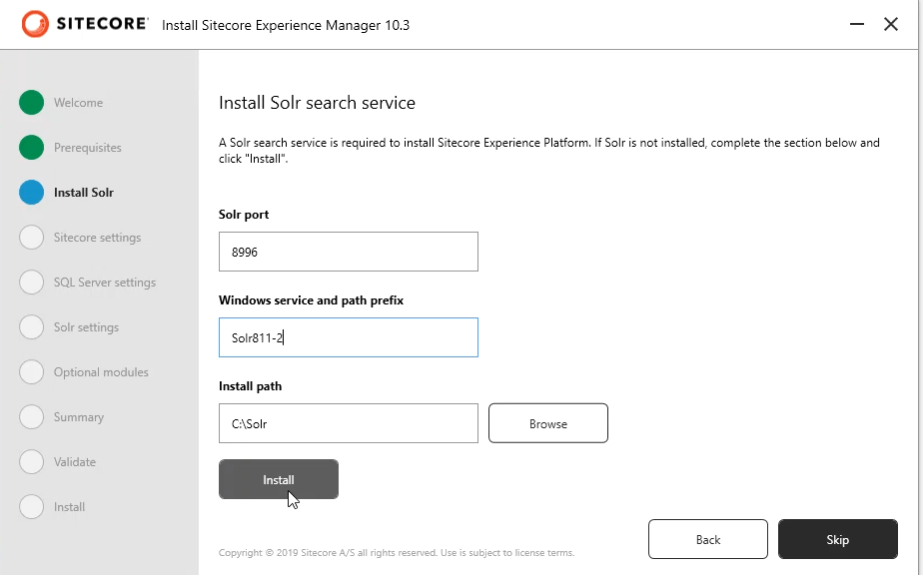
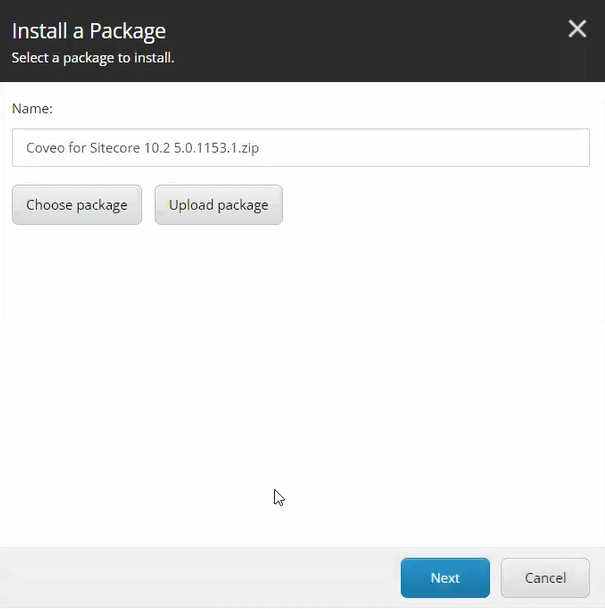
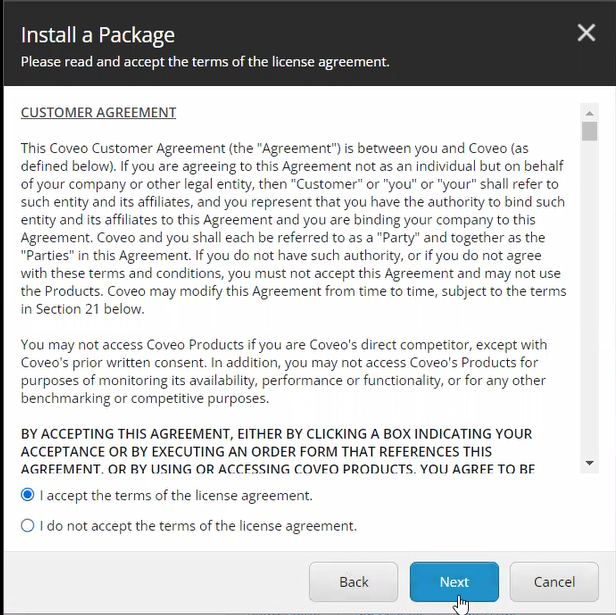
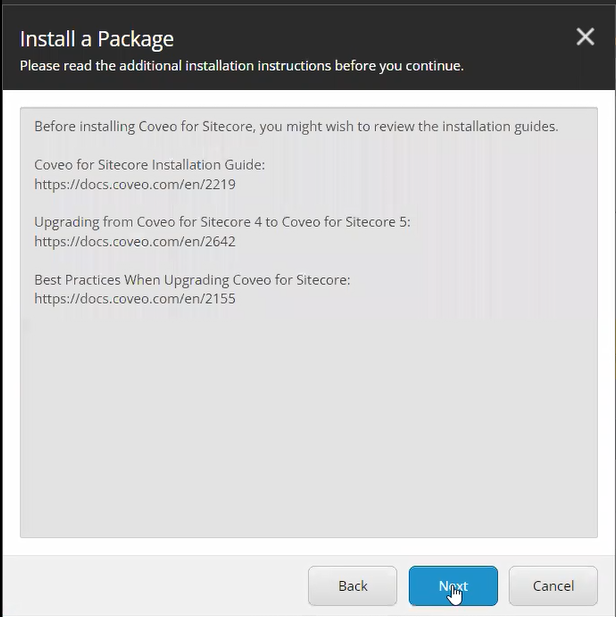
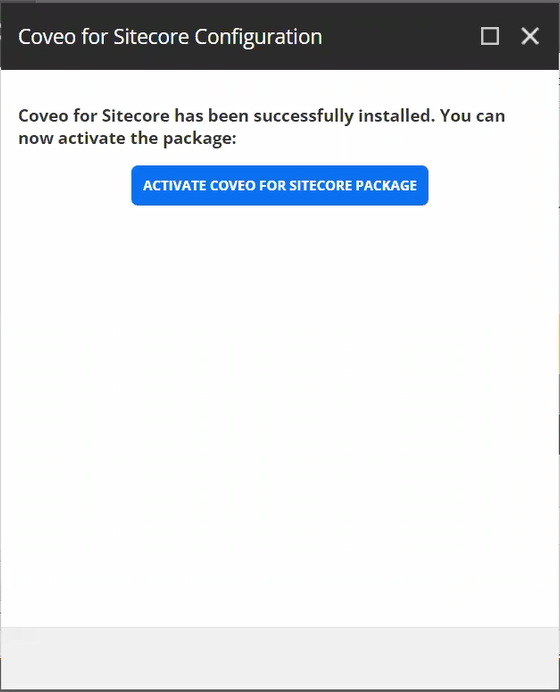
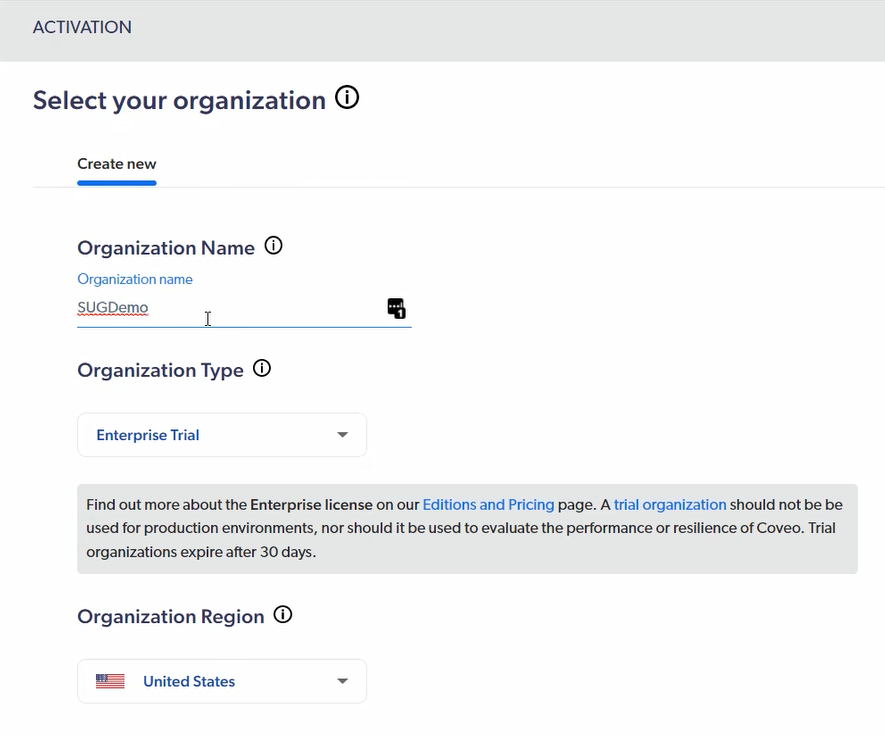
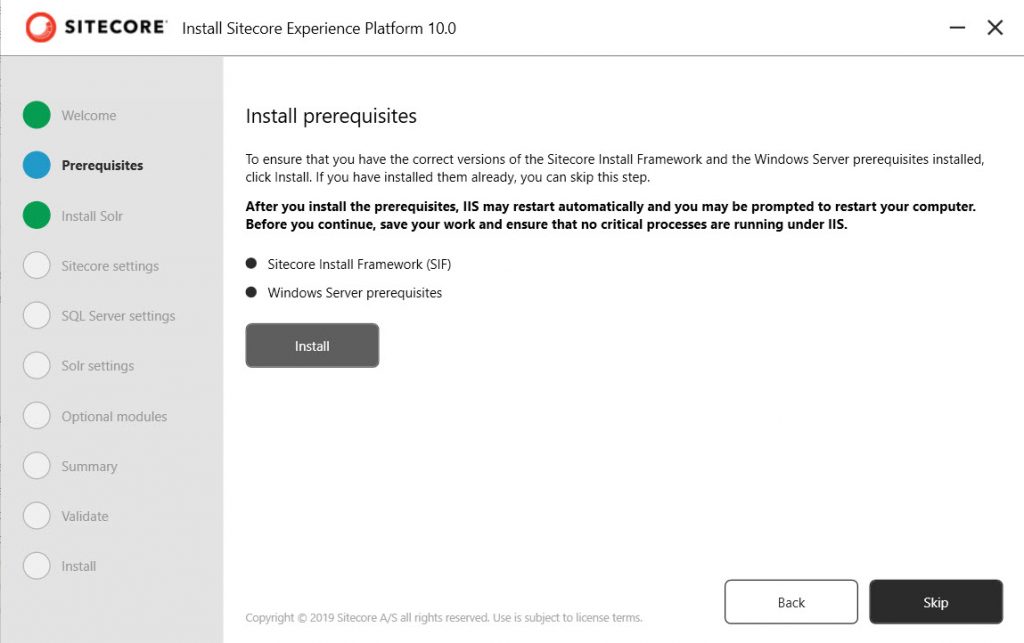
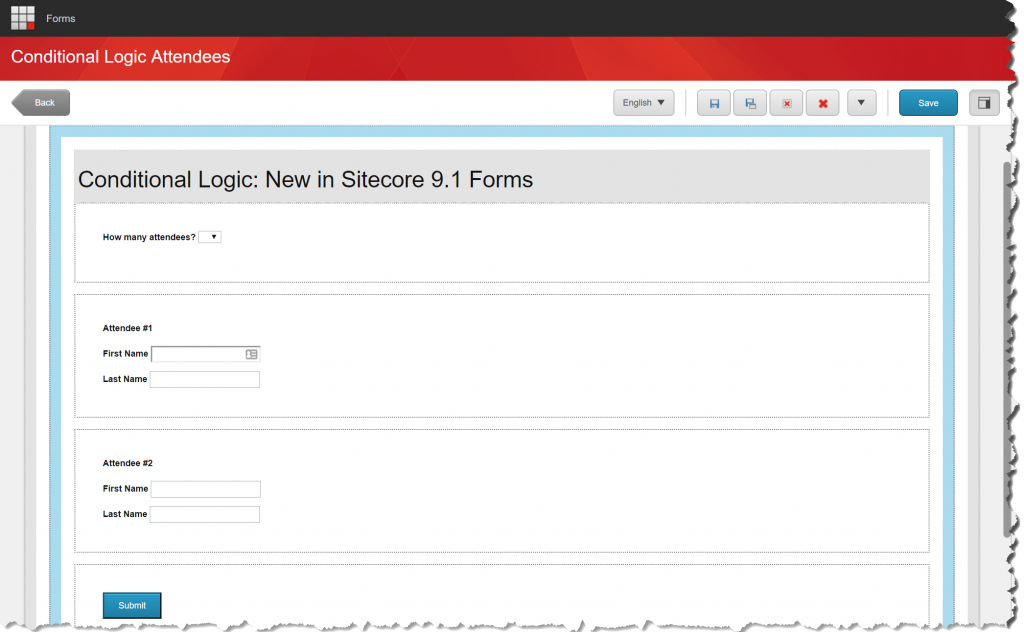
Recently, while upgrading an Optimizely CMS solution to .NET 10, we came across an issue where the Language Manager gadget completely disappeared from CMS Edit Mode.
The application was functioning normally, content editing worked as expected, and there were no build or startup errors. However, editors noticed that the Language Manager gadget was no longer available.
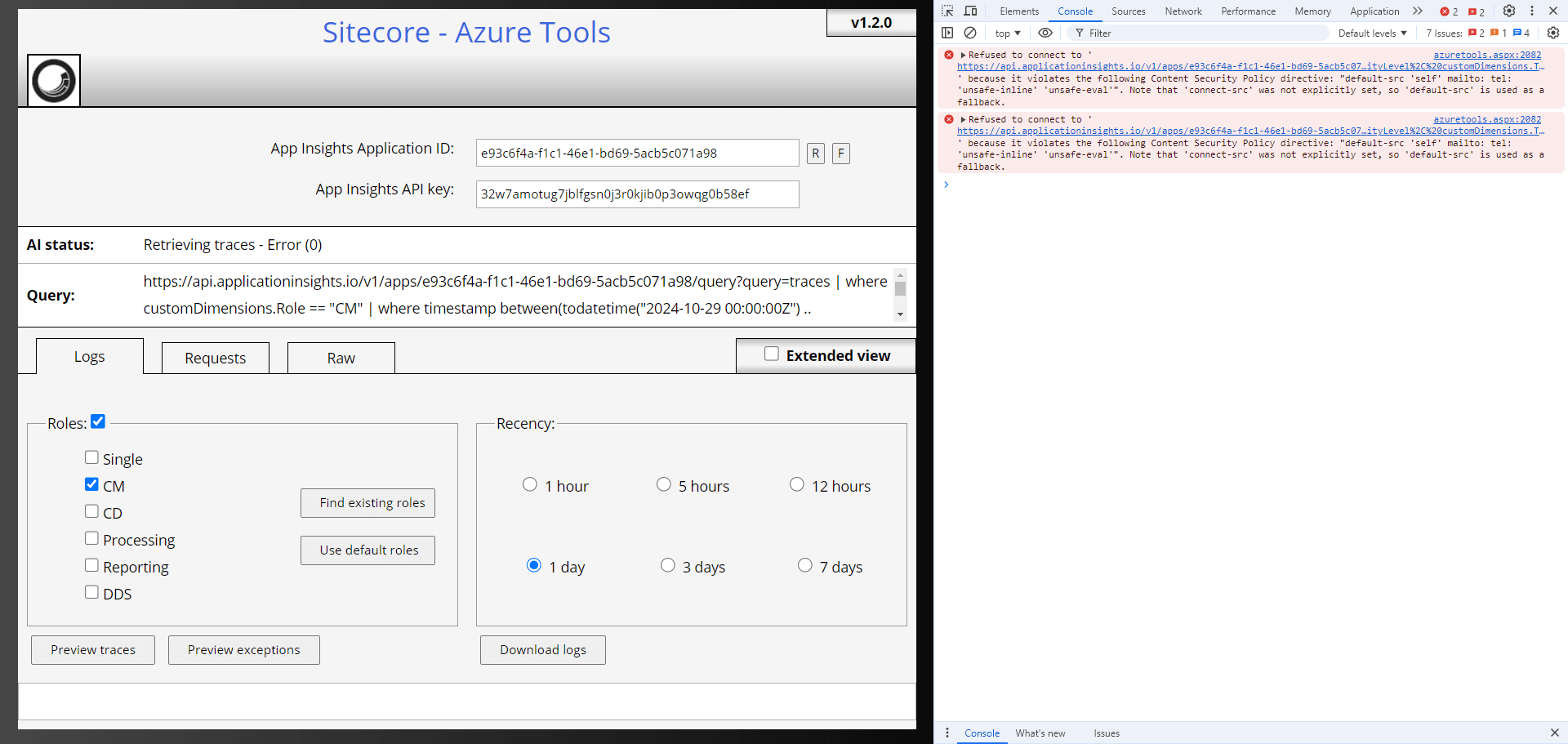
What made the issue difficult to troubleshoot was the complete absence of meaningful error messages.
In this blog, I will walk through the issue, the troubleshooting journey, and the simple configuration change that ultimately resolved it.
Environment
The affected solution was running the following versions:
- .NET 10
- Optimizely CMS 12.34.4
- EPiServer.CMS.UI 12.34.4
- EPiServer.Labs.LanguageManager 5.5.3
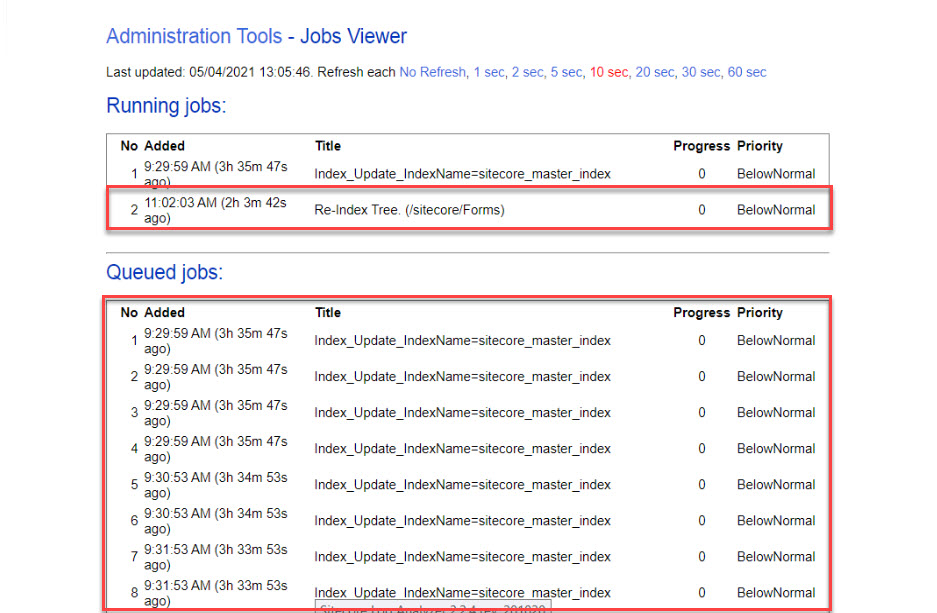
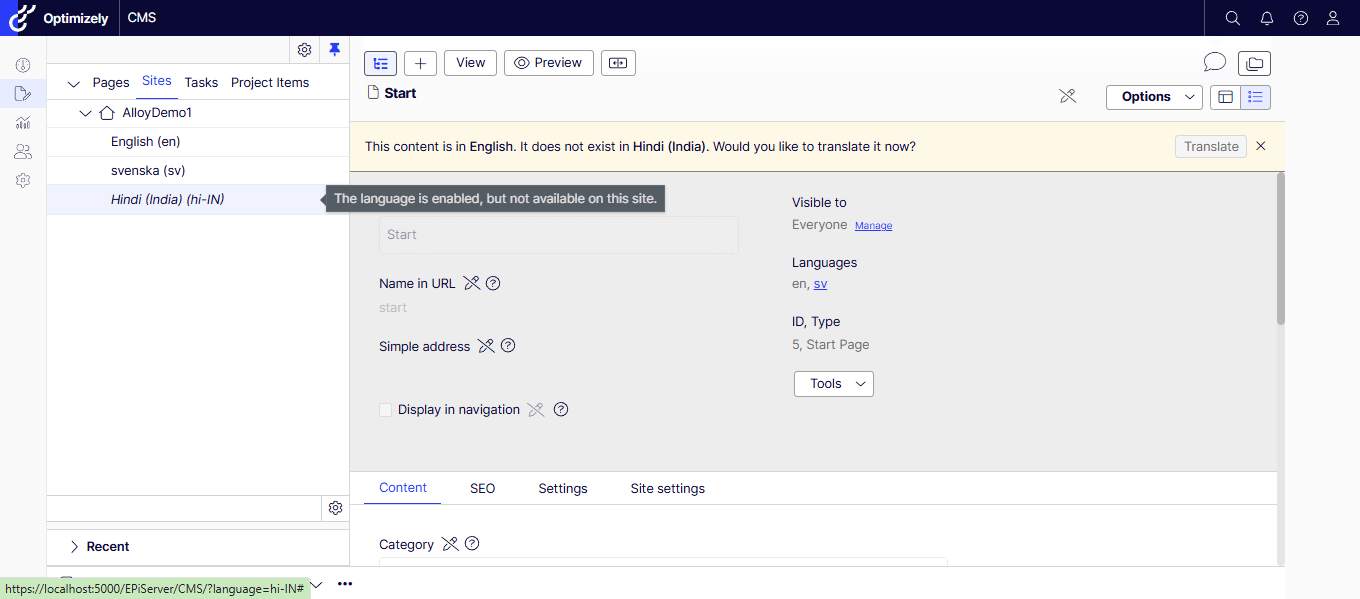
Immediately after the upgrade, the Language Manager gadget disappeared from the CMS editing interface.
Symptoms
Editors reported the following:
- Language Manager gadget missing from Edit Mode
- Gadget not available in the “Add Gadgets” list
- Reinstalling the package did not help
- Browser cache clearing had no effect
- Application started successfully without errors
The issue was consistent across environments and users.
Initial Checks
As part of the troubleshooting process, we verified the obvious areas first.
Verify Package Installation
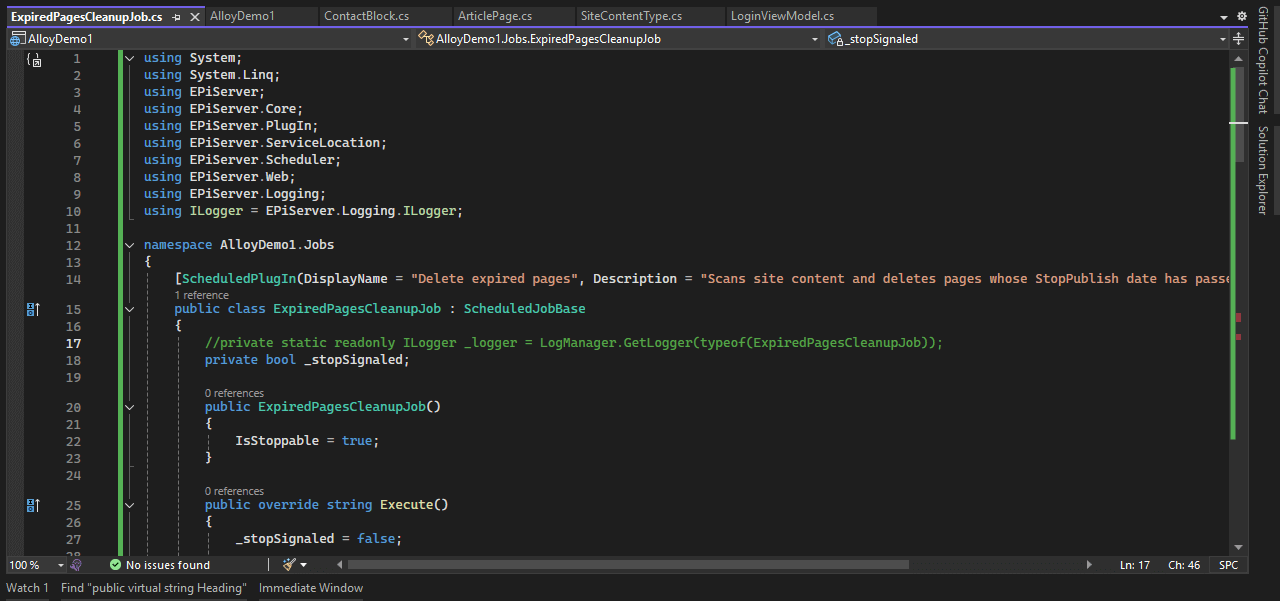
The Language Manager package was installed correctly.
<PackageVersion Include="EPiServer.Labs.LanguageManager" Version="5.5.3" />
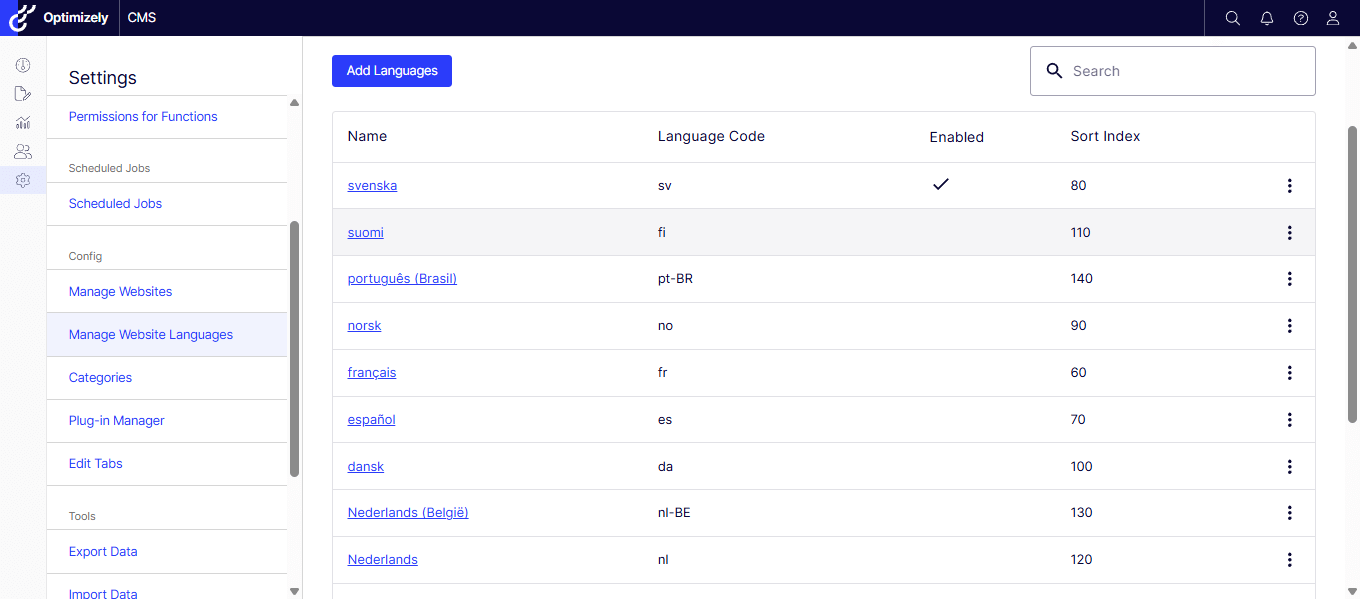
Verify Language Configuration
We confirmed that all required languages were enabled within Optimizely Admin Mode.
Since multilingual content was configured correctly, the problem was clearly elsewhere.
What Was Causing the Issue?
After working with Optimizely Support, the investigation pointed towards a .NET build configuration setting that was affecting assembly discovery.
The application itself was running correctly, but dependency information required by certain Optimizely add-ons was being trimmed during the build process.
Because of this, Language Manager was not being initialized correctly, resulting in the gadget disappearing from the CMS UI.
The tricky part was that there were:
- No compilation errors
- No startup failures
- No obvious exceptions
The feature simply disappeared.
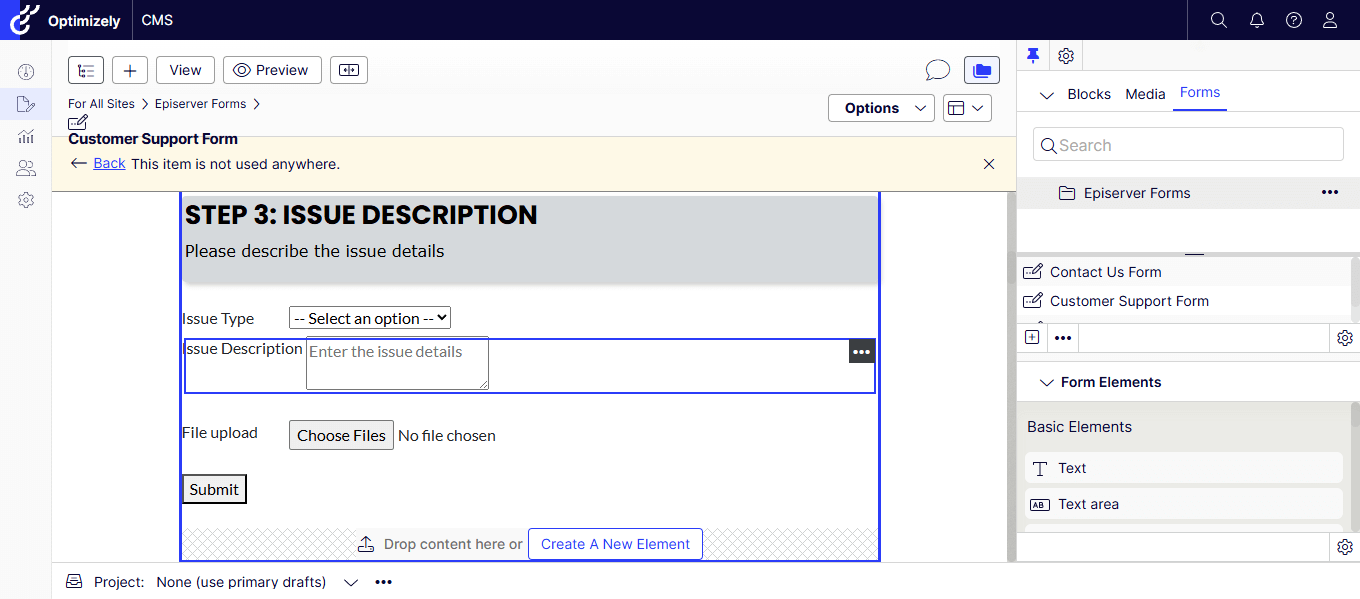
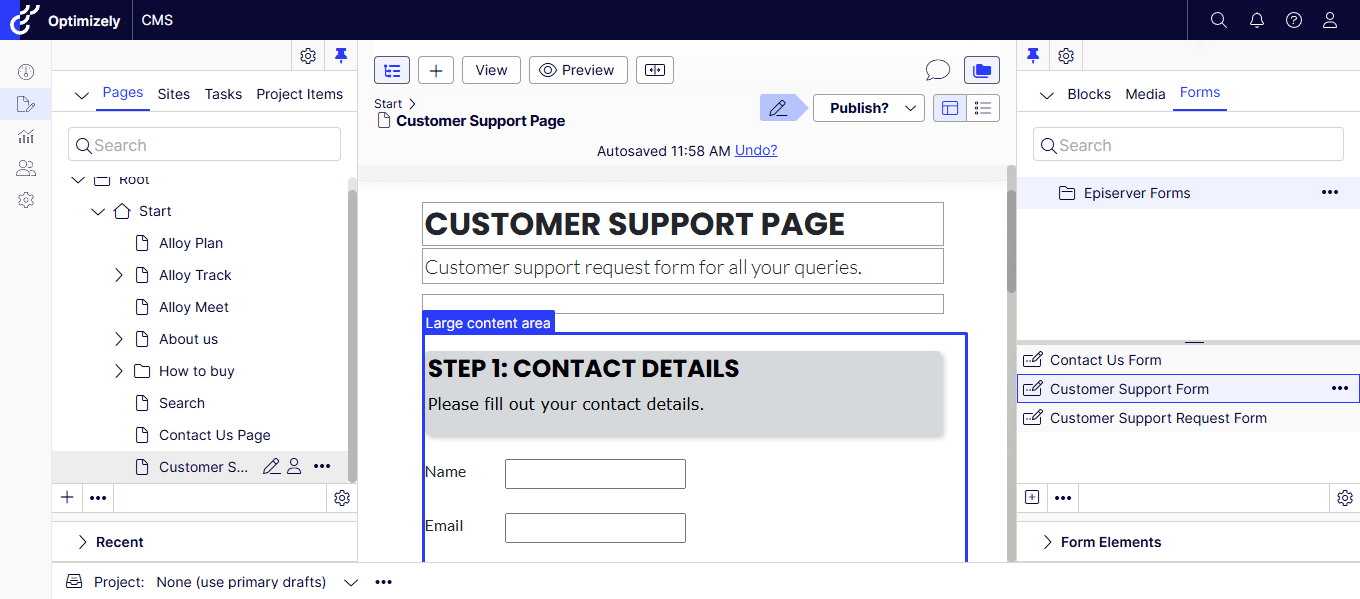
The Fix
The issue was resolved by adding the following property to the project file:
After adding the setting:
- Rebuild the solution
- Redeploy the application
- Restart the site
The Language Manager gadget immediately became visible again.








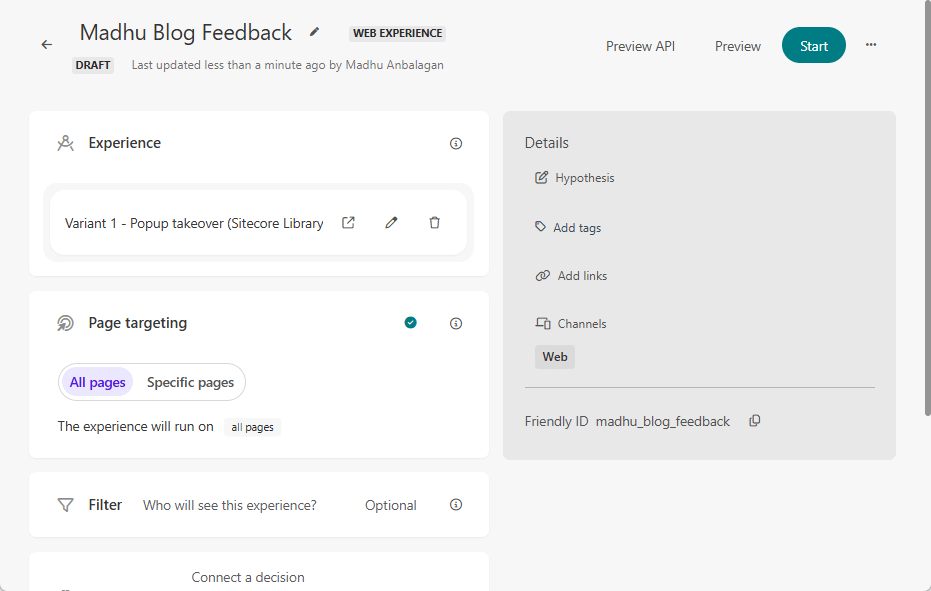
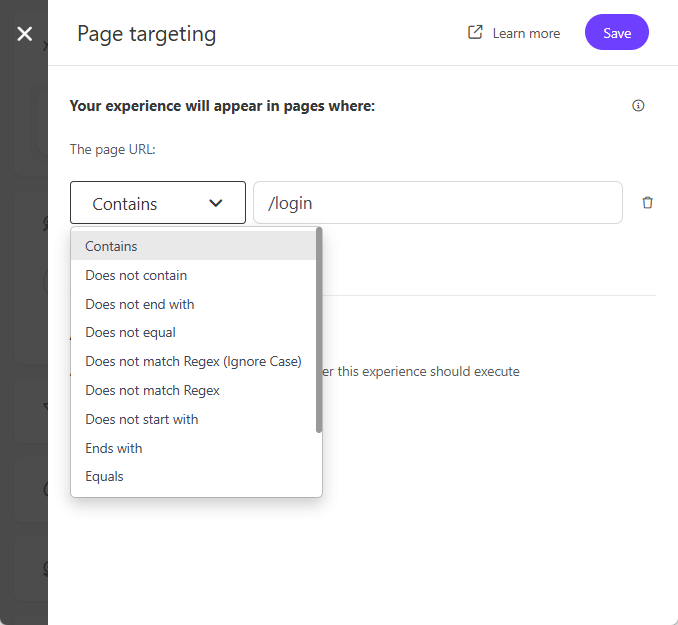
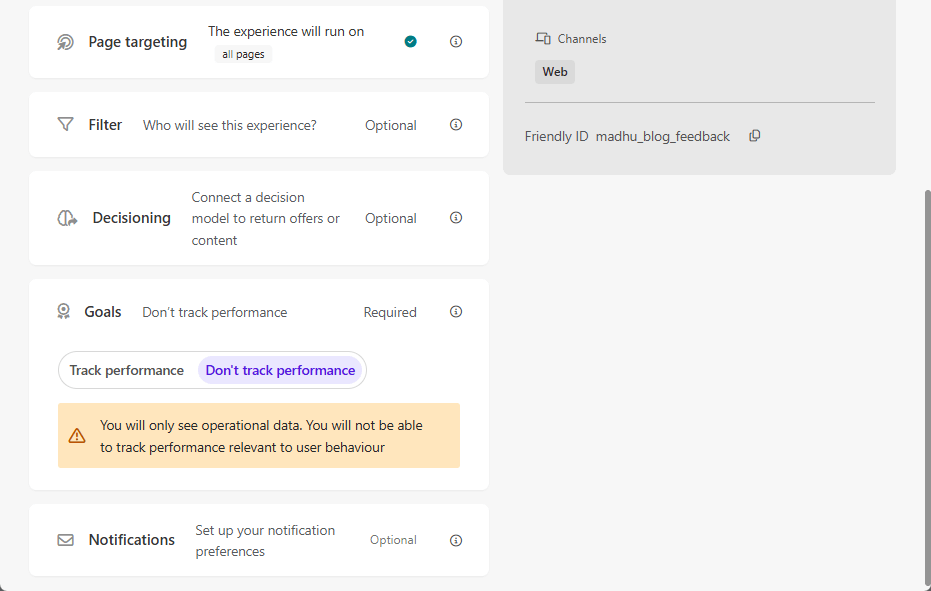
































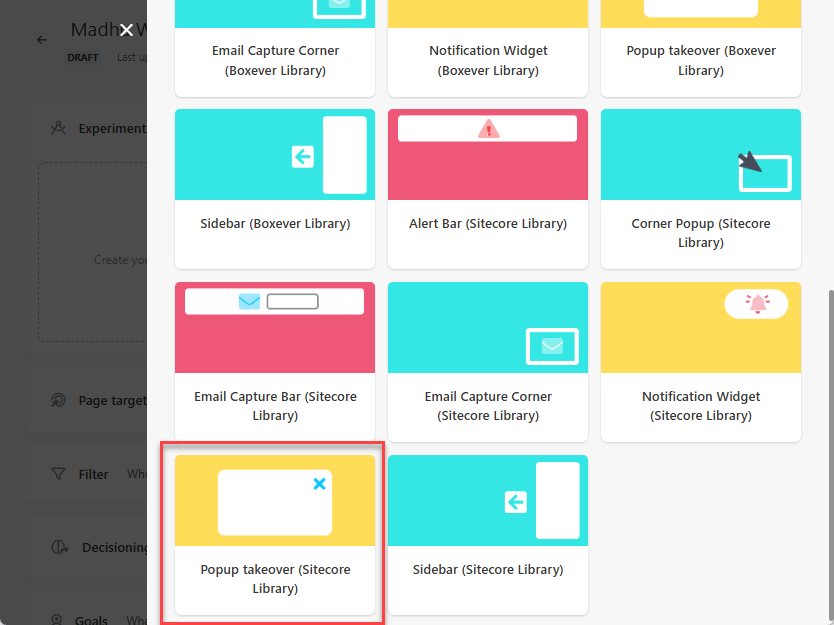
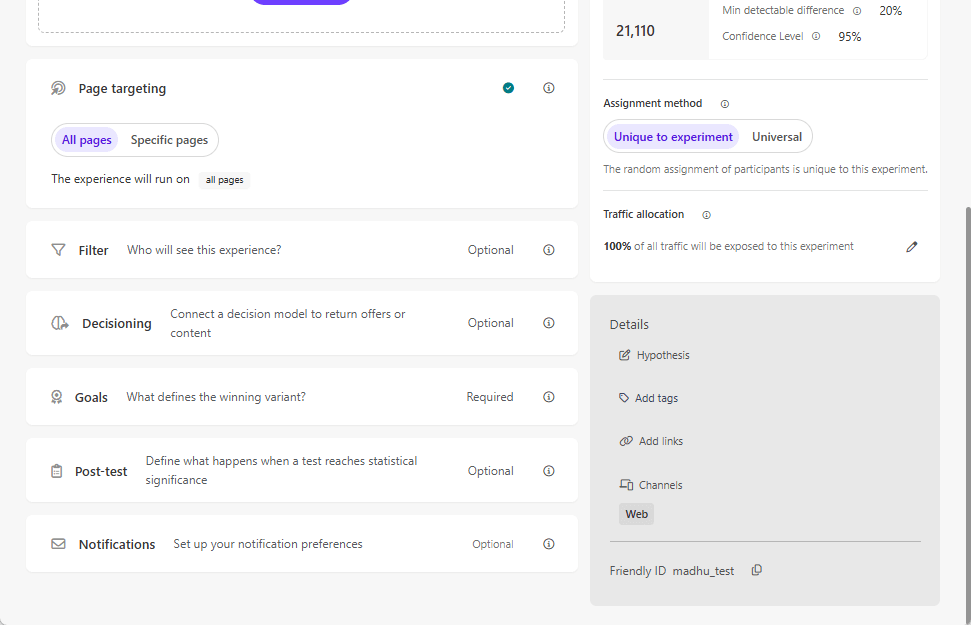
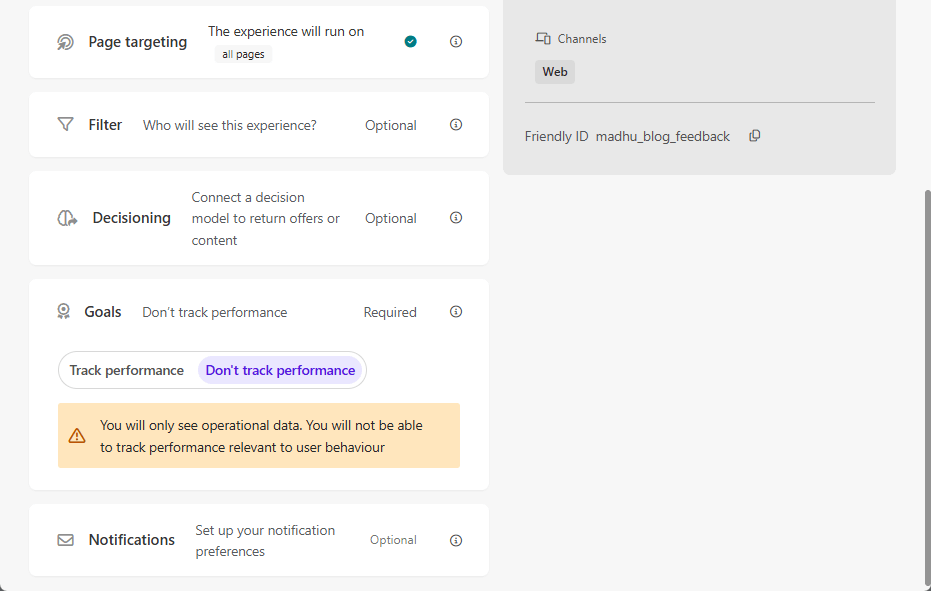
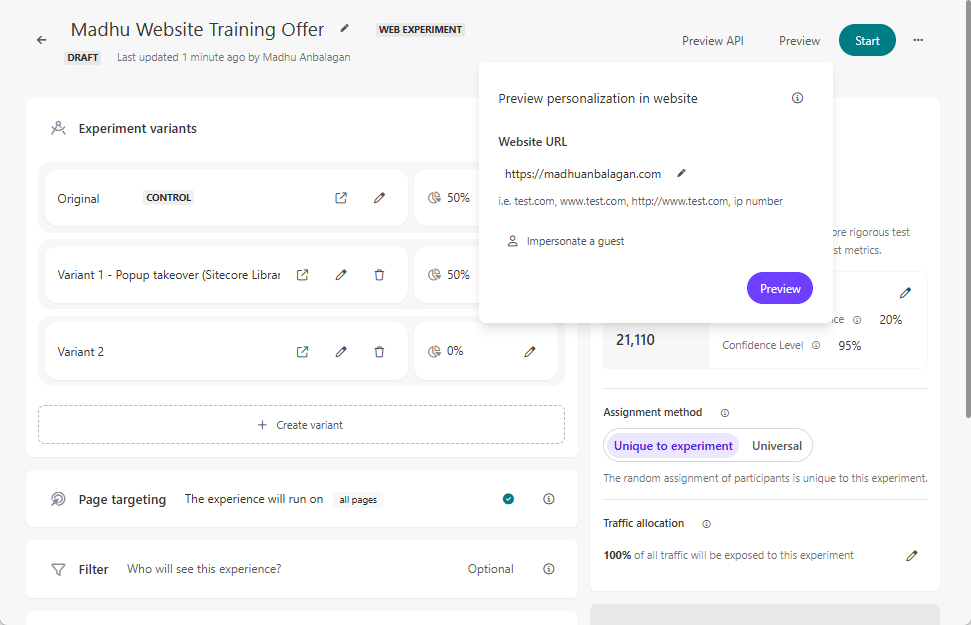
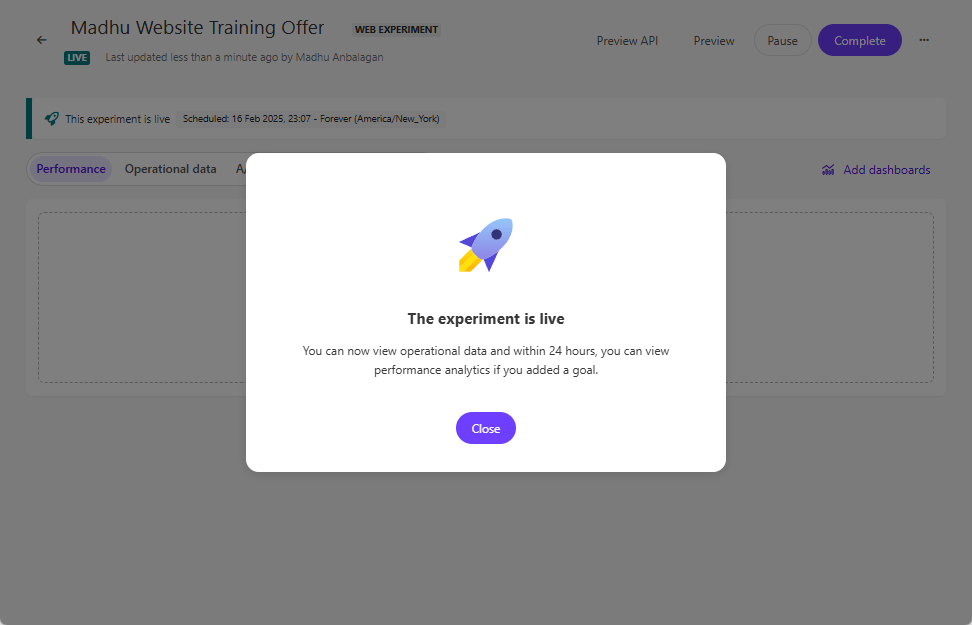
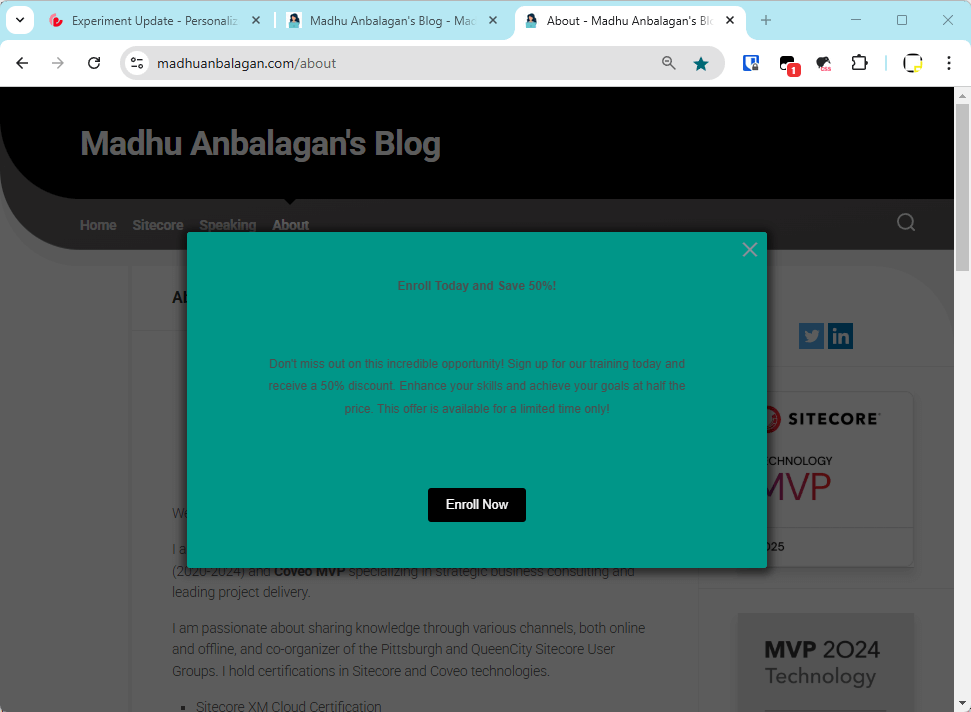
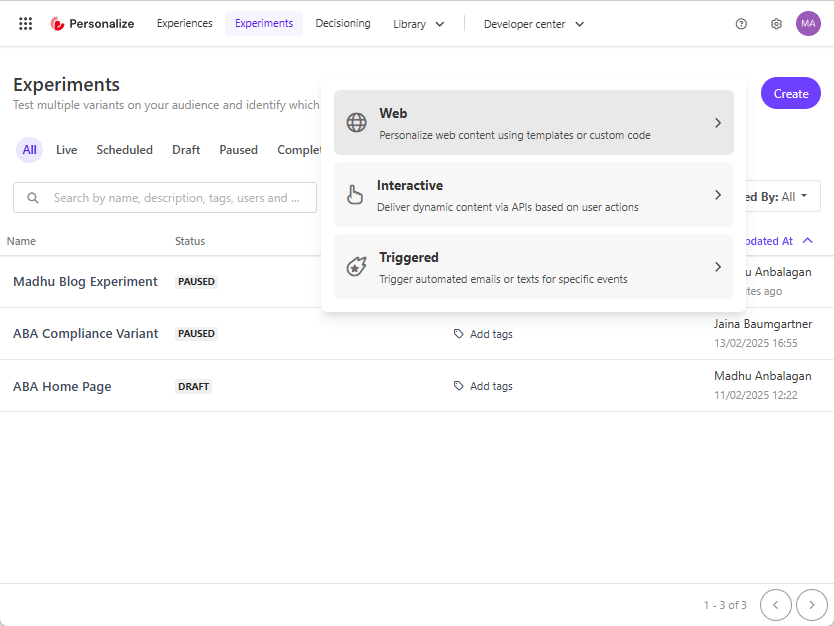 Types of Experiments:
Types of Experiments:
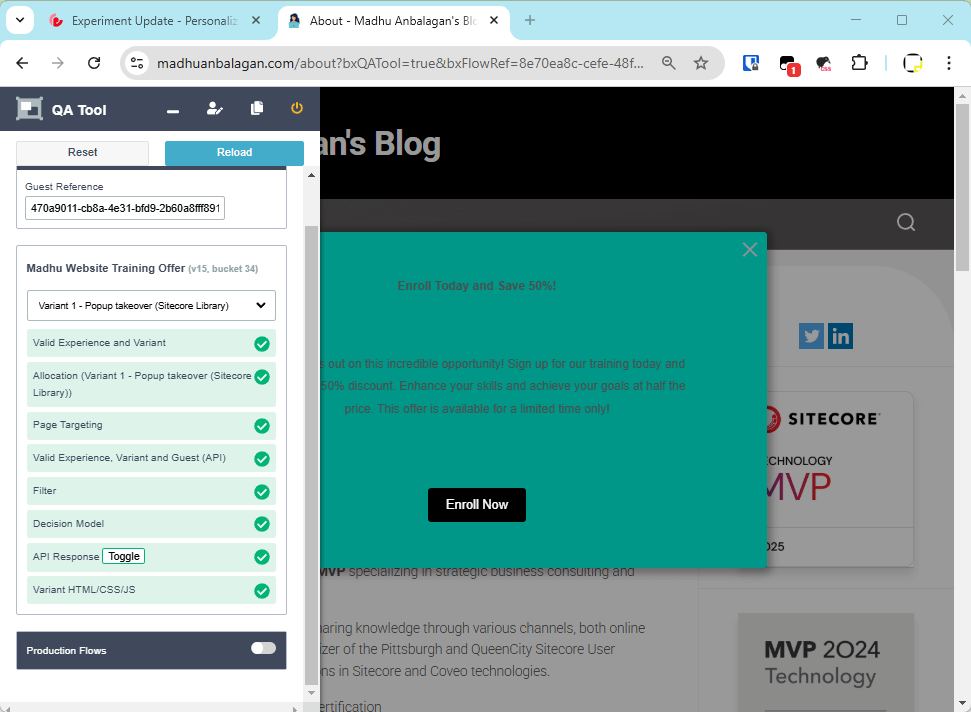



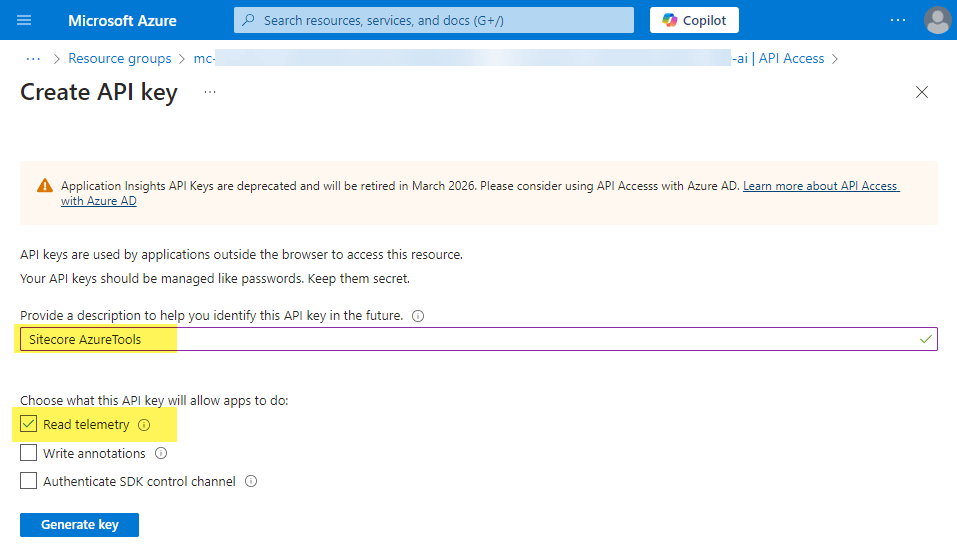
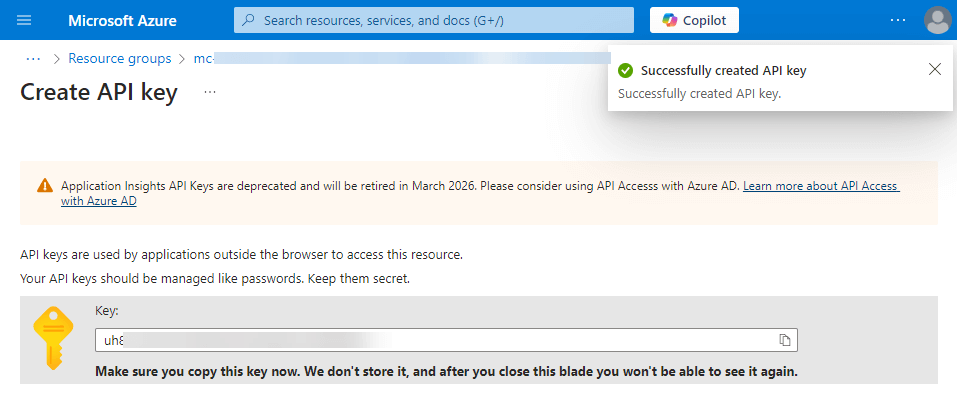
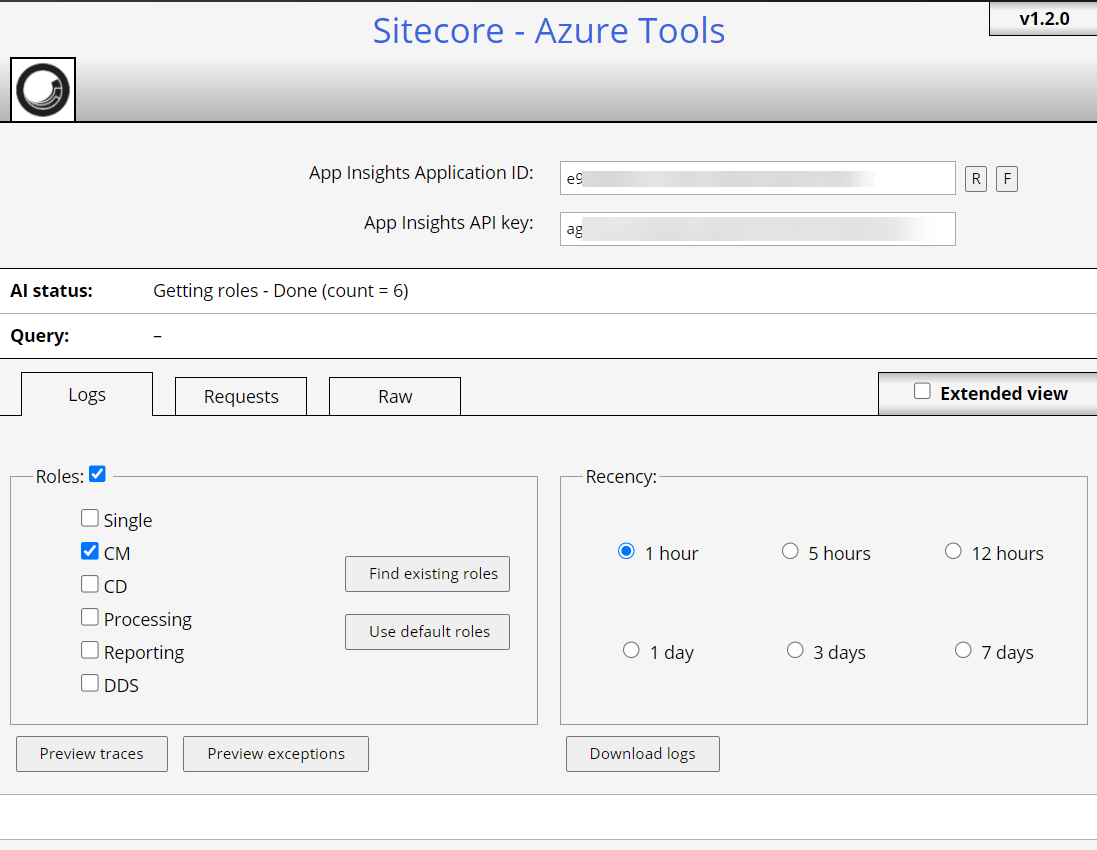
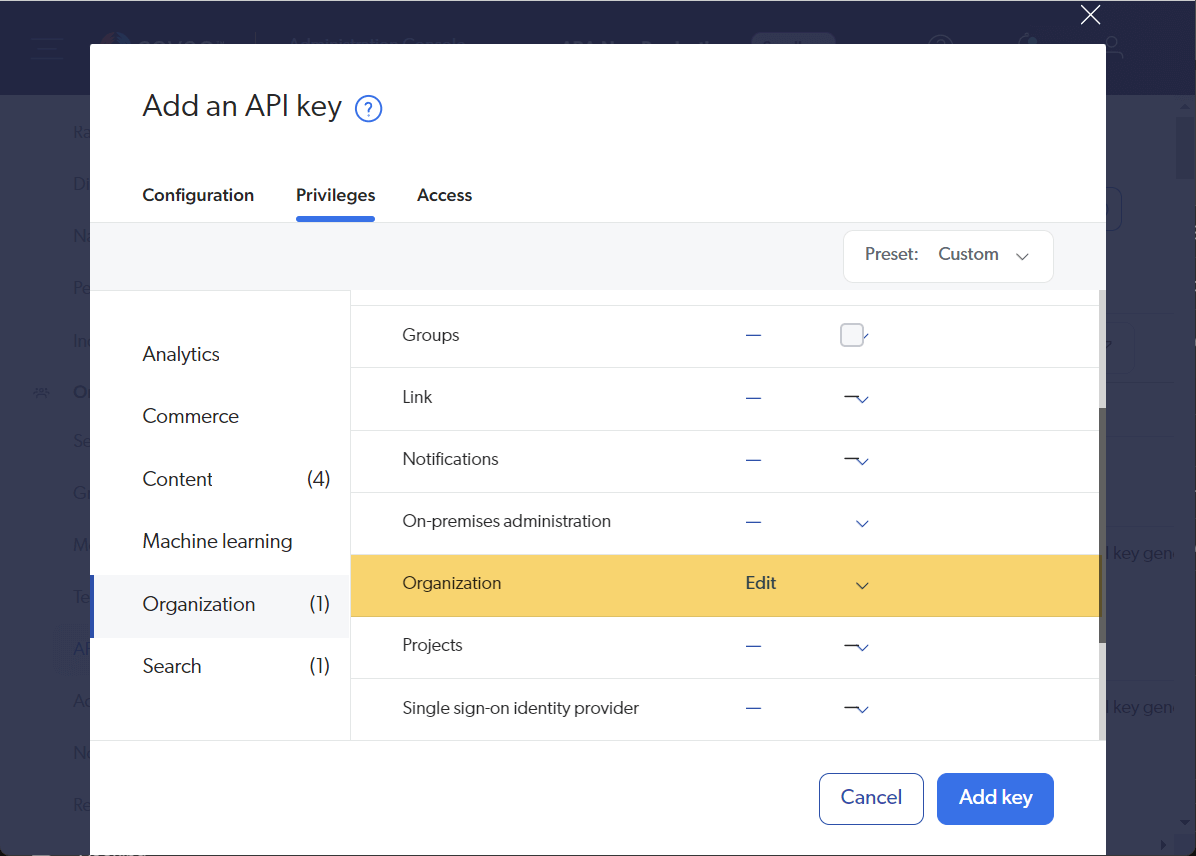
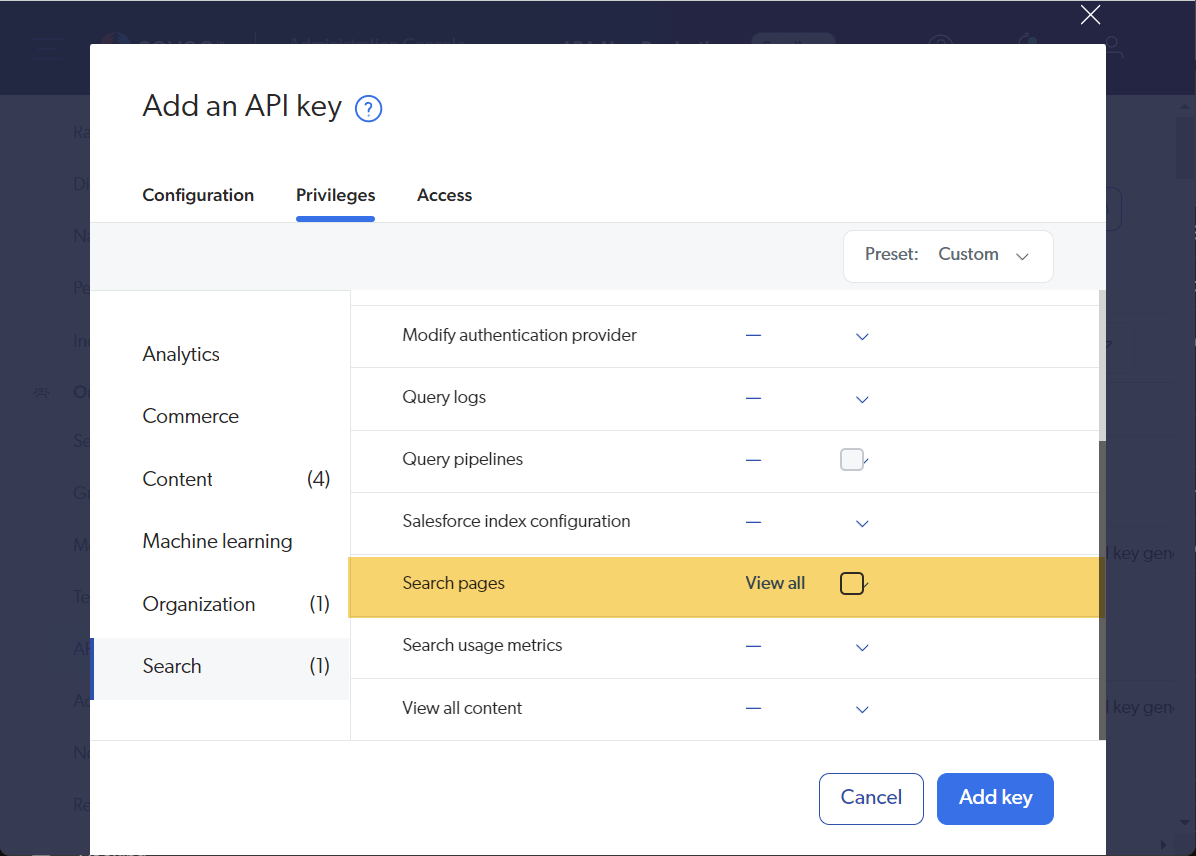
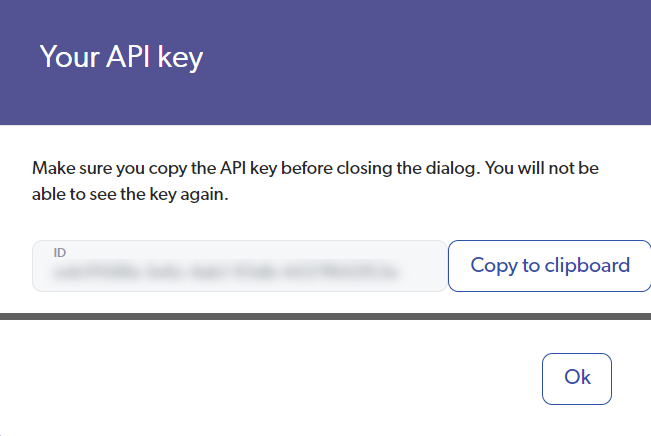
 API Key:
API Key: