
Problem
We have some secure PDFs in Media Library that were not getting indexed in Solr – They couldn’t be extracted using the PDFSharp library.
The logs were showing the error while extracting secure files
16804 12:04:53 ERROR DefaultMediaItemTextExtractor: Cannot extract content from media item with id ‘{442006A5-8CB6-4ABE-8855-786D2A870201}’.
Exception: PdfSharp.Pdf.IO.PdfReaderException
Message: The PDF document is protected with an encryption not supported by PDFsharp.
Source: PdfSharp
at PdfSharp.Pdf.Security.PdfStandardSecurityHandler.ValidatePassword(String inputPassword)
at PdfSharp.Pdf.IO.PdfReader.Open(Stream stream, String password, PdfDocumentOpenMode openmode, PdfPasswordProvider passwordProvider)
at PdfSharp.Pdf.IO.PdfReader.Open(String path, String password, PdfDocumentOpenMode openmode, PdfPasswordProvider provider)
at Sitecore.ContentSearch.ContentExtraction.Readers.PdfSharpReader.ReadAll(String filePath)
at Sitecore.ContentSearch.ContentExtraction.Common.DefaultMediaItemTextExtractor.ExtractTextFromMedia(MediaItem mediaItem)38536 12:04:53 ERROR DefaultMediaItemTextExtractor: Cannot extract content from media item with id ‘{442006A5-8CB6-4ABE-8855-786D2A870201}’.
Exception: PdfSharp.Pdf.IO.PdfReaderException
Message: The PDF document is protected with an encryption not supported by PDFsharp.
Source: PdfSharp
at PdfSharp.Pdf.Security.PdfStandardSecurityHandler.ValidatePassword(String inputPassword)
at PdfSharp.Pdf.IO.PdfReader.Open(Stream stream, String password, PdfDocumentOpenMode openmode, PdfPasswordProvider passwordProvider)
at PdfSharp.Pdf.IO.PdfReader.Open(String path, String password, PdfDocumentOpenMode openmode, PdfPasswordProvider provider)
at Sitecore.ContentSearch.ContentExtraction.Readers.PdfSharpReader.ReadAll(String filePath)
at Sitecore.ContentSearch.ContentExtraction.Common.DefaultMediaItemTextExtractor.ExtractTextFromMedia(MediaItem mediaItem)
Solution
- If you would like to disable the media indexing by applying the following patch – Sitecore.Support.DisableMediaIndexing.config
- If you like to index the media content, Sitecore recommends using the following libraries IFilter, Apache Tika, or SolrCell.
- Azure web apps have a limitation in using the IFilter library so I ended up using Apache Tika.
Steps to Integrate:
- Download the Apache Tika server file –tika-server-1.22.jar.
- Sitecore recommends Apache Tika version 1.22 refer to the compatibility table for your version
- Save the server file in a folder on SOLR server e.g: c:\tika
- In PowerShell navigate to the path and execute the following command to install.
java -jar tika-server-1.22.jar
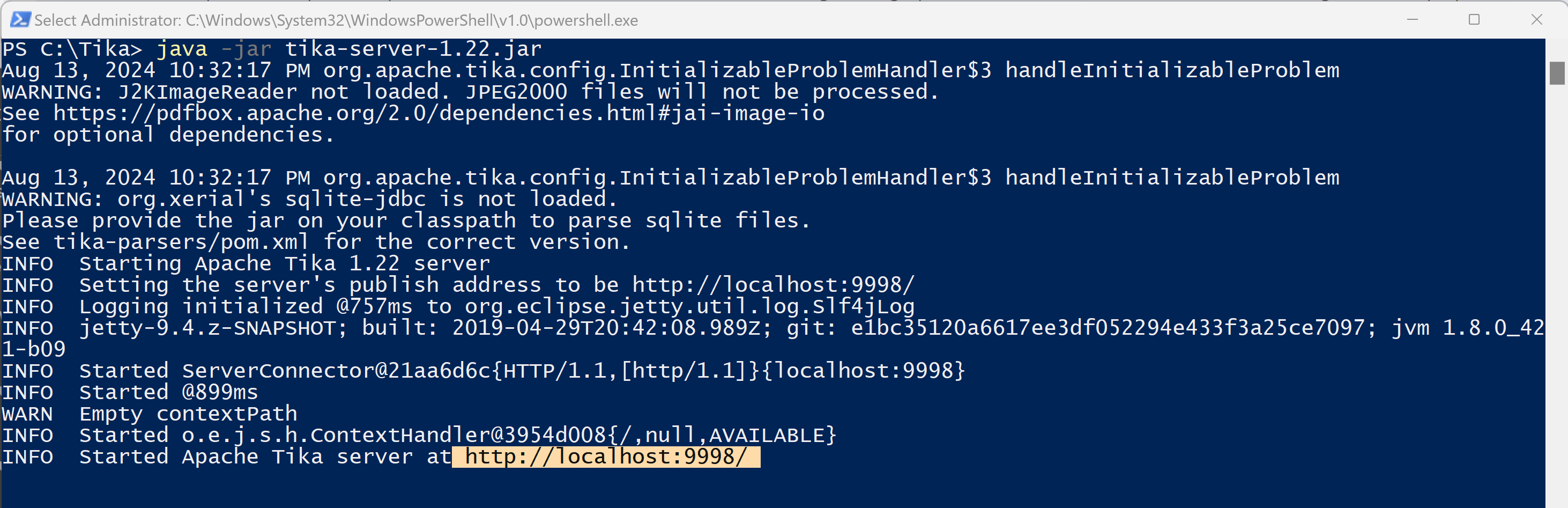
Note: The default hostname is localhost and the port is 9998.
If you would like a specific hostname and port number that could be included in the installation command as parameters
java -jar tika-server-1.22.jar –host=<Tikahostname> –port=<portnumber>
After the installation is completed open the following URL http://localhost:9998 to see if it is working as expected. You should see the welcome message!

- Add the following patch file into App_Config/Include/zzz folder to replace DefaultMediaFileTextExtractor from Sitecore.ContentSearch.ContentExtration.
- Last step – Let’s add Tika URL into ConnectionStrings.config file.
<add name=”tika” connectionString=”http://localhost:9998″ />
- Let’s test quickly – Rebuild a Tree in the Developer Ribbon for one item or you could Rebuild the entire index.
- Once the indexing is completed check and see if we have the media item available in the index.
Quick Tip: To search for a particular item in Solr, use the following query in the parameter q on your index page
_uniqueid:*[item id in lowercase without braces]*

- Secure PDFs are indexed successfully in Solr! Yay!
- If you are using SearchStax Solr Cloud, reach out to the support to get it added to your instance.
Hope this helps.
Happy Sitecoring!








1 Response
[…] Aug 28, 2024 – Sitecore: Apache Tika Integration for Secure Media File Indexing […]